An Overview of Ravelin’s Technology
I write this post as an overview of each aspect Ravelin’s technology stack; almost not worthy of the hours and days that each component has taken to implement. This overview will not attempt to deep dive into any given topic but, where possible, link out to sources and reference material. The intention is to write more specifically and in far greater detail over the coming months.

Context
The Ravelin stack was entirely green field, which meant no legacy systems to maintain and complete freedom with technology choices. If you think back to the end of 2014, Kubernetes, GRPC and Microservice Frameworks didn’t exist or, if they did, were in alpha/beta. The term containers had just become mainstream and Docker was the new hot thing on the block. Google Cloud Platform (GCP) was basically just App Engine, Compute and Storage. For more information on why we moved from AWS to GCP earlier this year, see the post on Bigtable.
Requirements
Unlike most startups we had large paying customers from day one, which meant that our api had to handle ~600-1000 requests a second along with storing years’ worth of their data. Furthermore:
- Instant scalability, we needed to be easily able to handle the spikes in our clients’ traffic. From once a year events like Black Fridays to daily demands on rainy days for taxis. Ideally, we would be able to scale within 5 mins for operational workflow like api machine and less than 60 mins for more predictable events. Secure, we store our clients’ data and need to ensure our systems (and their data) is well protected.
- Cost efficient operational database and data warehouse, needed for machine learning model training and prediction. Each additional client that onboards would send us all their historic data, our data warehouse is a warehouse of clients’ data warehouses.
- Responsive, for most of our clients, we sit in the checkout flow; PSPs already take the best part of a few seconds to auth transaction, which is understandable as someone within the 4 party model there is probably a mainframe or two. We aim to score a customer within 300ms of every api request.
- Obviously, highly available.
Aspiration
The ability to scale horizontally every part of our infrastructure within minutes, including load balancers, service machines, api machines, databases, queues, cache etc. Have no single point of failure. Continuous Integration (although not Continuous Delivery, story for another post) via CircleCI.
Infrastructure
Puppet for setting up 3rd party software, like Zookeeper, Postgres, Redis, ElasticSearch etc. Terraform, to ensure our infrastructure is repeatable and treated as code under version control; in fact we even build terraform branches within our CI tool.
Cloudflare, to help protect against DDOS. AWS Cloudfront for caching, internal path based routing and TLS/SSL exchange. OpenVPN, private subnets and Nat boxes to audit and limit traffic in and out of our system. Fully managed load Balancers to provide practically infinite scale. Preemptible (spot) instances for batch jobs, to keep costs down.
Our dev-service, which manages infrastructure within our infrastructure so no developer needs (cloud provider) API keys to change infrastructure. We also built a small service to deal with provisioning, health-checking and orchestration os services called Atlas. Effectively, Kubertenes (k8s) before kubernetes was widely available.
Finally, Papertrail for centralised logging, DataDog for centralised metrics and OpsGenie for alerting.
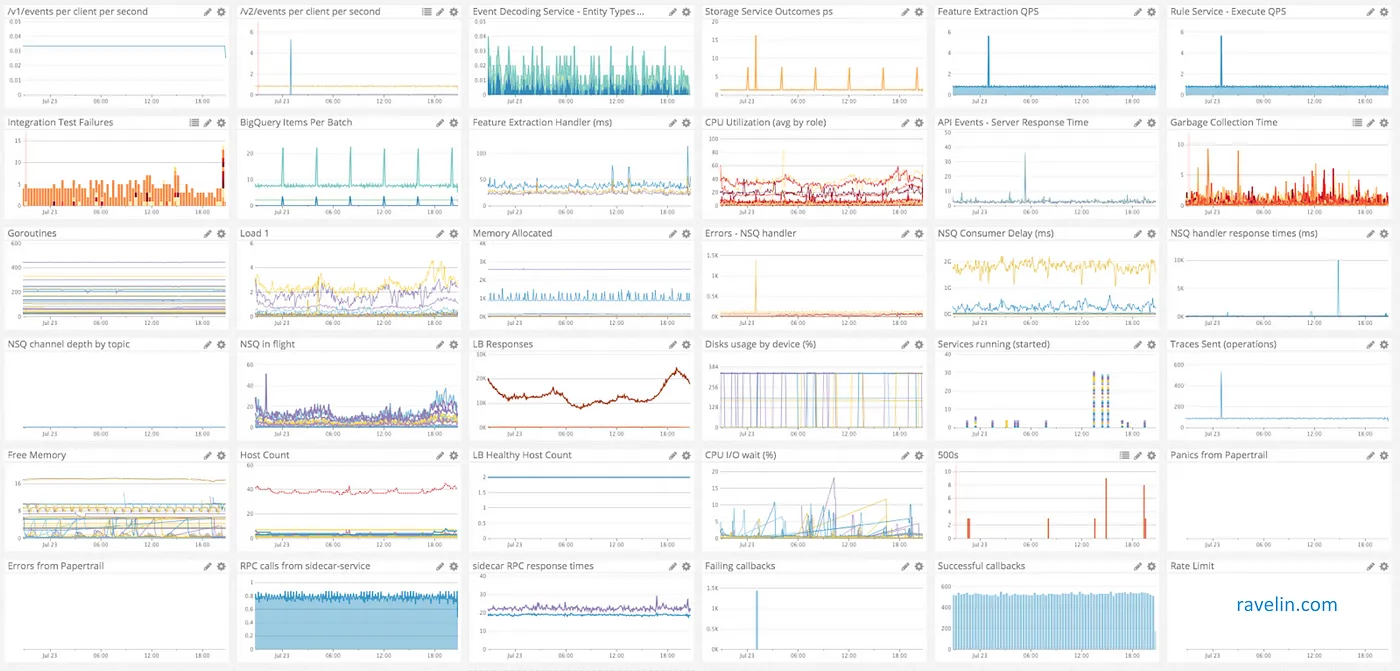
For those with a keen eye you will notice mainly failing integration tests; note that this is our staging environment metrics.
Local Dev Environment
Docker used for Local Dev only. Rocket currently used for Python but we are exploring kubernetes as GKE makes it very easy to manage.
Software
Microservices (SOA)
Decoupling each part of the Ravelin application into small components that do one job very well. Easier to deploy since they are autonomous. Engineering staff with experience building a microservices platform at Hailo. Beware, microservices architecture have many more moving parts, distributed systems are harder write, debug and test,; remote calls are slow and carry the risk of failure, also requires more infrastructure, more tooling and added operation complexity.
Go
Very quickly compiles down to a single small binary, easy to write unit tests and has garbage collection. Works really well with protobuf, easy to work with concurrency and is relatively fast when compared to other languages.
Two Python Services + Sidecars
Python has: very mature libraries for machine learning, is very popular, easy to learn and is strongly typed (even though dynamic). We also have a python JSON schema validation service, as Go JSON validation errors are not great. Both services use a small sidecar written in Go to act as a proxy for the platform/infrastructure.
Protobuf and JSON :(
Protobuf to communicated between services and for some parts of our data model due to it being much faster to unmarshal/marshal (and smaller) than JSON. We still use JSON for our external API because is it ubiquitous and well supported in every language.
NSQ
A simple, in memory, distributed queue. Response times typically in the sub 1 millisecond range. We publish anywhere between 5 to 50 times during an API request into our system. With this level of speed and simplicity there are some drawbacks: messages are not durable, delivered at least once and there is no guarantees of being ordered.
Bigtable
Horizontally scalable column based, NoSQL databased fully managed by GCP. HBase is essentially an opensource implementation of Google Bigtable. When scaling up a new Bigtable node, it typically takes sub 20 mins to completely join and we see a linear efficiency increase.
BigQuery
Highly scalable, on-demand data warehouse. As we ingest all our clients history data we needed an exceptionally cost efficient method of storage and retrieval. Bigquery costs are $5/terabyte/month for storage and $5/terabyte of data queried.
PostgreSQL
Where transactions are needed and to power very low traffic services (e.g. internal dashboard, service deployment audit log etc).
Zookeeper
For global locking and service discovery. We have used Zookeeper in the past and found it to be scalable, reliable and very consistent (probably through years of production systems seems to be battle hardened). Although, it does require some more work to ensure when autoscaling the new nodes successfully join the cluster.
Redis
For our cache. Has useful data structures (above and beyond key value) and depending on the benchmarks you read as fast as memcache.
ElasticSearch
For rich querying for clients’ data and to power searches within our client facing dashboards. We are very selective with the data that we put into ElasticSearch and in almost all cases have to enrich the queried results with data from Bigtable.
S3 & Cloudfront
S3 coupled with Cloudfront are unparalleled in static hosting capabilities. We host all Ravelin static files, including all dashboards on s3 fronted by Cloudfront configured with our TLS (SSL) certificates.
Key Management Service (GCP KMS and AWS KMS)
For storage of our certificates and other secrets.
OpenVPN / GCP Identity Aware Proxy (IAP)
For developer access into our infrastructure we use typically use OpenVPN with 2fa auth. Although, recently we have been testing IAP and slowing moving more internal dashboard to sit behind it, removing the need for the VPN.
Luigi
To automate the ML data pipeline and training, essentially our directed acyclic graph for the data science team.
In Memory Graph Database
Our graph queries sit in the operational flow and therefore has to traverse entire graphs and respond within a few milliseconds. Most existing graph databases are relatively slow therefore we had to build an in memory graph database from scratch.
JSON Schema -> Doc Generation
Keeping API documentation up-to-date is always a struggle. Therefore, directly tying the code to docs was essential. For developer.ravelin.com we autogenerate 90% of the copy and forms from our JSON Schemes.
Dashboards
Angular 1 & 2 with TypeScript.
Summary
It is nice to start from scratch and pick the right tool for the right job. It is not perfect and there will always be a long list of improvements; however, the technology stack scales well, is cost efficient and fulfils all the requirements.